
How Do I Think About Setting Spark Shuffle Partitions in 2025?
TLDR: A Quick Guide to setting Spark.Shuffle.Partitions, No Deep Dive Required

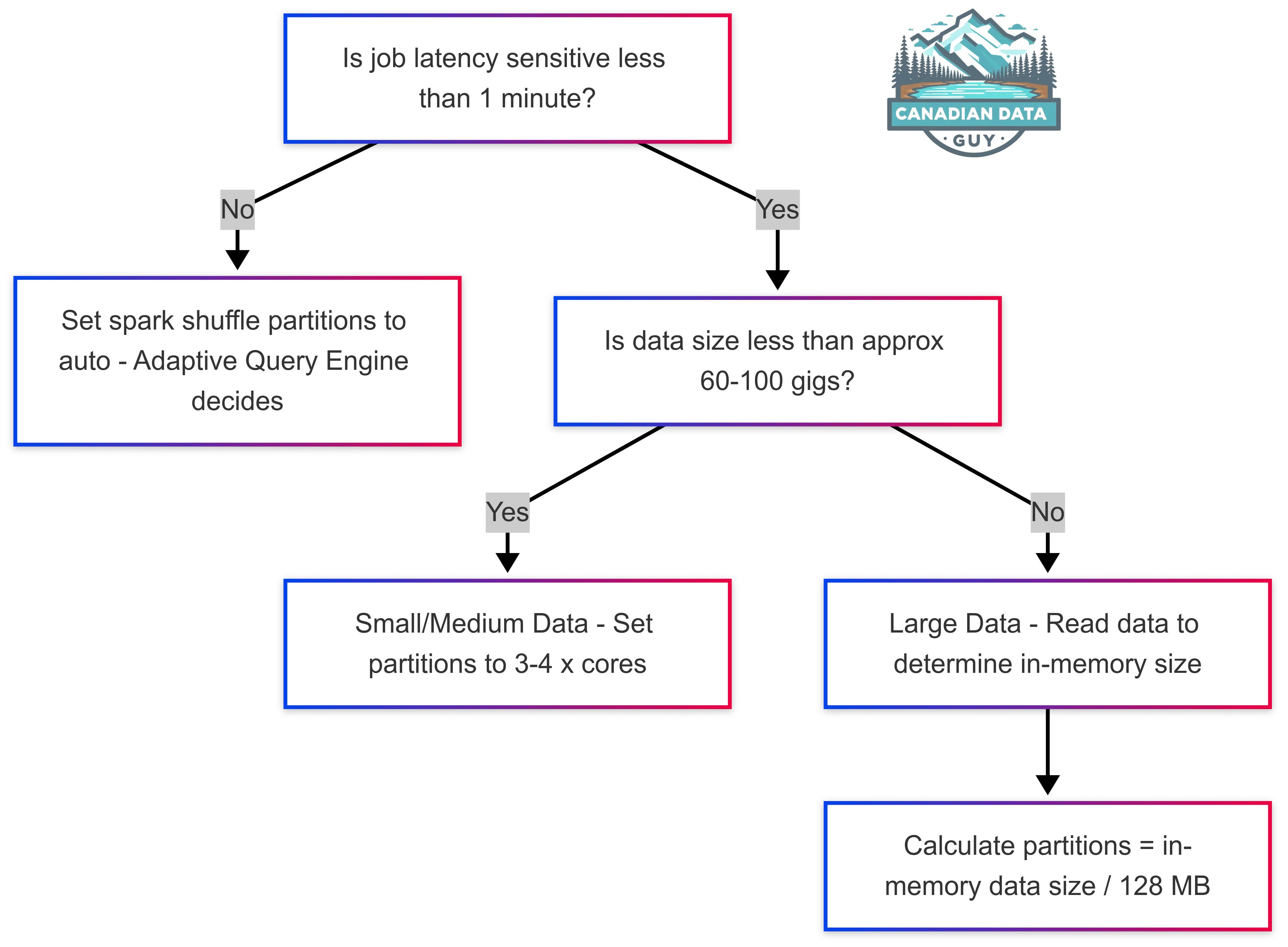
In 2025, overthinking about Spark shuffle partitions has become less critical thanks to modern innovations in the Spark ecosystem. In earlier years—say, 2015 to 2019—the default setting of 200 partitions often proved either too high or too low, prompting manual tuning and much deliberation. However, with advances like the Adaptive Query Engine, many of these decisions are now automatically managed, ensuring optimal performance without constant human intervention. This guide provides a streamlined decision tree to help you quickly determine if any manual adjustment is needed, so you can focus on higher-value aspects of your data processing work.
How to calculate in-memory data size
When assessing data size for partitioning in Spark, it's important to note that the on-disk size—such as data stored in S3—does not always reflect the in-memory size. This is because data formats like Parquet or Avro are highly compressed, and the actual memory footprint can be 2 to 8 times larger than the file size on disk. Understanding the in-memory size is essential for properly tuning your shuffle partition settings.
To accurately gauge this in-memory size, you can run the following Spark commands to trigger a computation and then inspect the Spark UI (specifically under the SQL/Dataframe tab) for the 'Shuffle read size':
# Read data (example: Parquet file) df = spark.read.load("examples/src/main/resources/users.parquet") # Save as no-op (does not write data, but triggers computation) df.write.format("noop").mode("overwrite").save()This approach helps ensure that you're basing your partitioning decisions on the actual memory requirements rather than the compressed on-disk sizes.
References
https://www.databricks.com/notebooks/gallery/SparkAdaptiveQueryExecution.html
https://www.databricks.com/discover/pages/optimize-data-workloads-guide
Keep This Post Discoverable: Your Engagement Counts!
Your engagement with this blog post is crucial! Without claps, comments, or shares, this valuable content might become lost in the vast sea of online information. Search engines like Google rely on user engagement to determine the relevance and importance of web pages. If you found this information helpful, please take a moment to clap, comment, or share. Your action not only helps others discover this content but also ensures that you’ll be able to find it again in the future when you need it. Don’t let this resource disappear from search results — show your support and help keep quality content accessible!