

Introduction
When a Spark Structured Streaming job fails mid-flight, how does it know where to resume? What prevents duplicate writes to your Delta tables? This article explores the elegant mechanisms that make Spark Structured Streaming fault-tolerant and exactly-once.
Key Insight:
The checkpoint directory and Delta Lake’s transaction log work together to ensure correctness even when clusters die between writing data and recording completion.
Checkpoint Directory Structure
When you start a streaming query, Spark creates a checkpoint directory with the following structure:
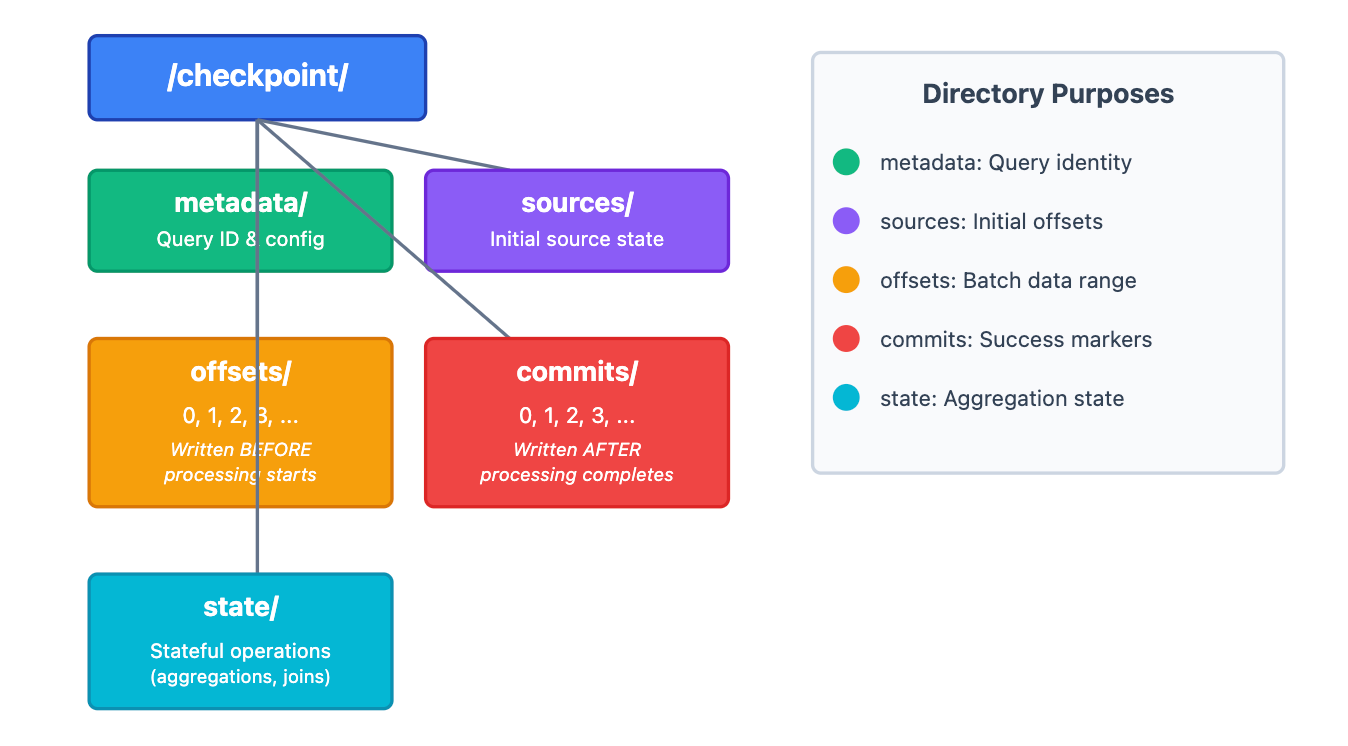
Critical Timing:
offsets/N is written before processing batch N starts.
commits/N is written after batch N completes successfully.
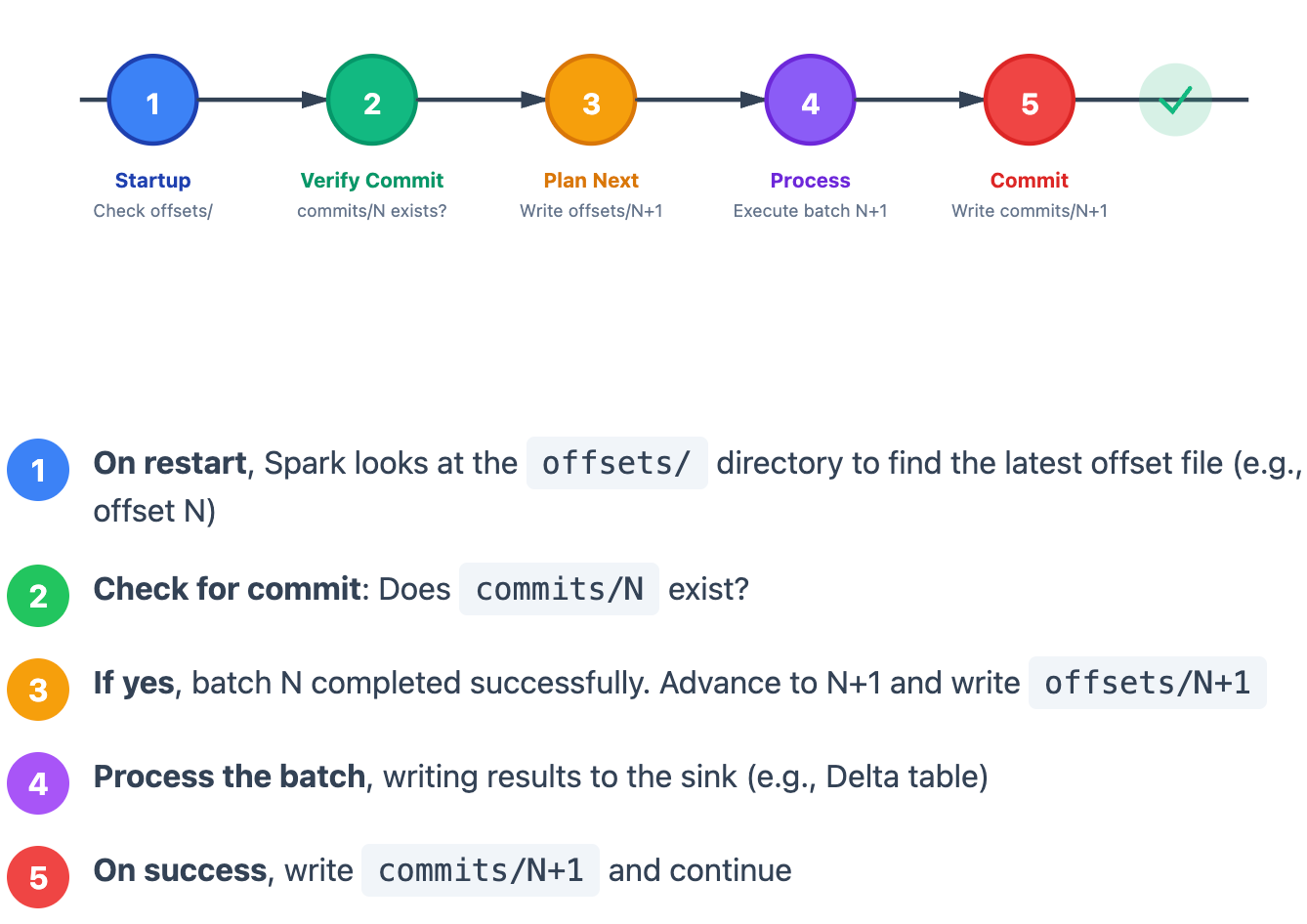
The Normal Happy Path
The Critical Failure Scenario
Here’s where things get interesting. What happens when the cluster dies after writing to Delta but before writing the commit file?
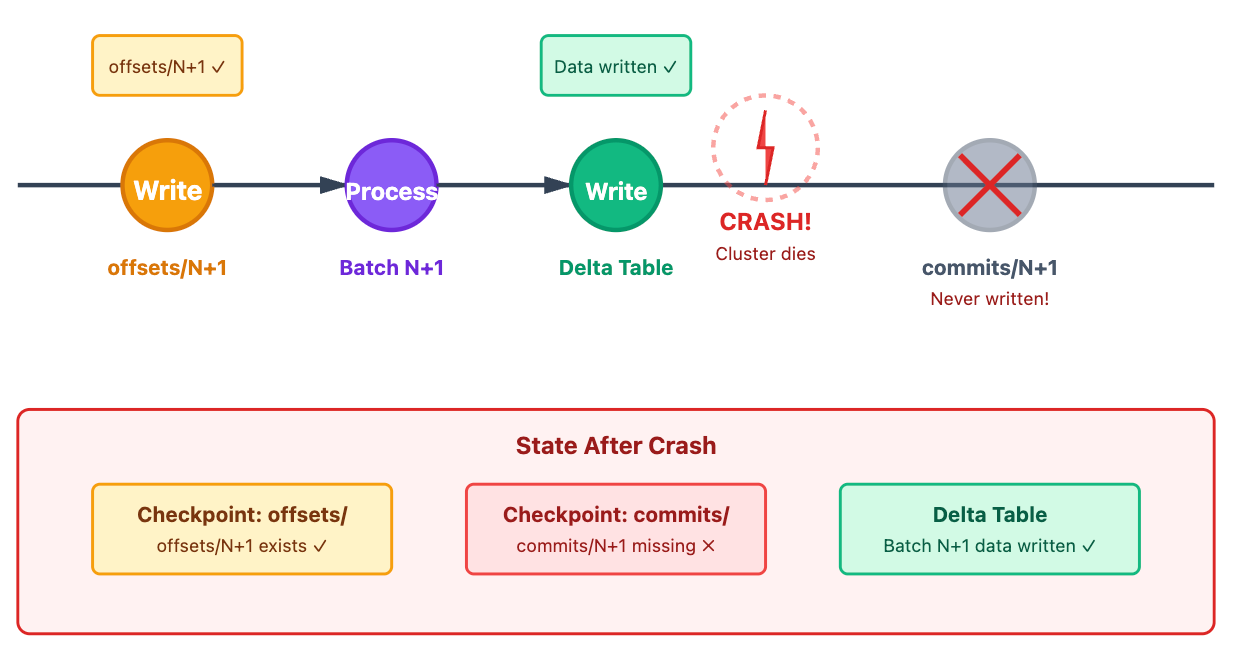
The Problem
Batch N+1 was successfully written to Delta Lake, but the commit file was never created. On restart, Spark will see:
offsets/N+1exists
commits/N+1does not existData is already in the Delta table
Question: Won’t re-running batch N+1 create duplicates? 🤔
Delta Lake’s Idempotency Magic
This is where Delta Lake’s transaction log saves the day. Delta records two critical pieces of metadata with every streaming write:
Note: The terms
epochIdandbatchIdrefer almost to the same thing - the monotonically increasing micro-batch number. I am trying to find more details to figure out the difference
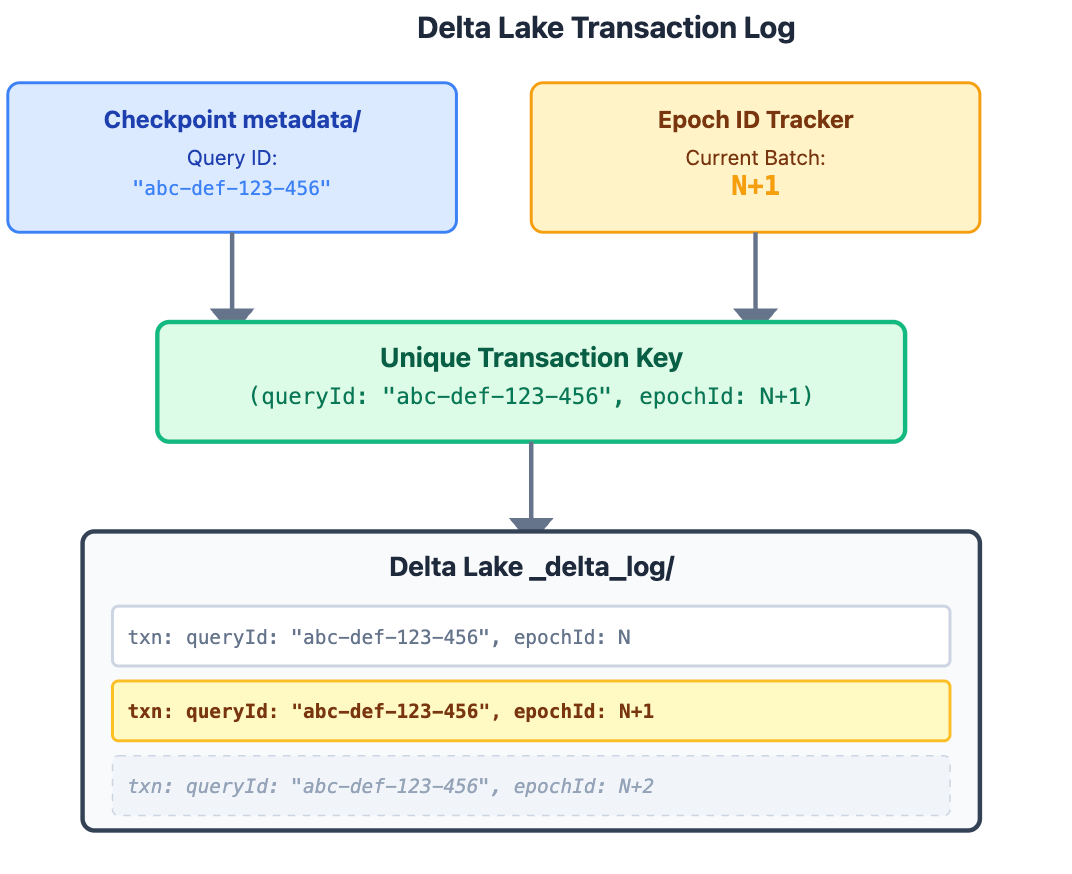
txnAppId (Query ID) The unique streaming query identifier from metadata/ .This ensures different queries don’t interfere with each other
txnVersion (Epoch ID) The micro-batch number (0, 1, 2, 3...) Monotonically increasing; each batch gets its own ID
The Solution
When Spark retries batch N+1, Delta Lake checks its transaction log:
Has transaction (queryId: “abc-def-123-456”, epochId: N+1) been committed?
If YES: Skip the duplicate write, create
commits/N+1If NO: Proceed with the write, then create
commits/N+1
Complete Recovery Flow
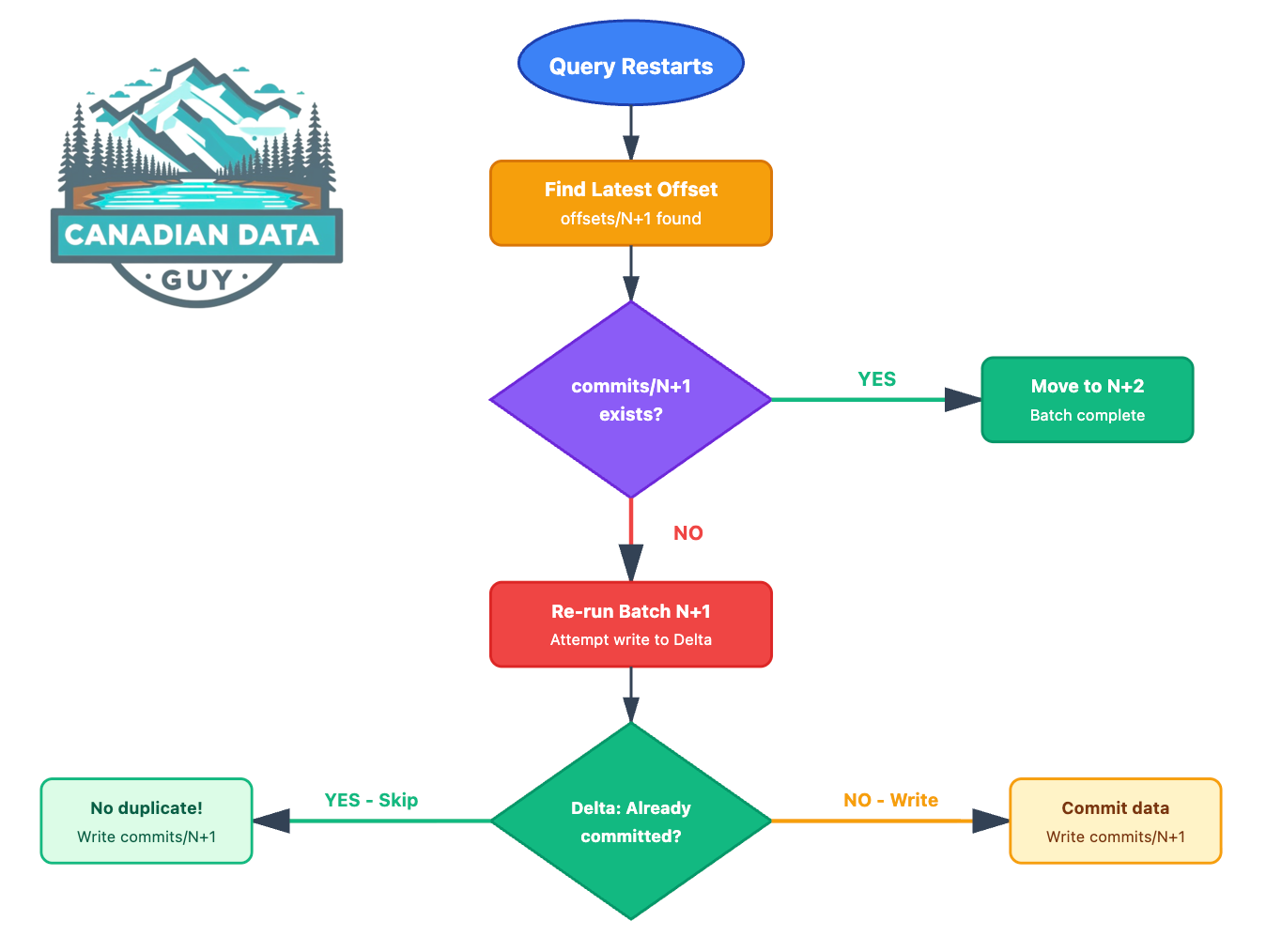
Key Insight: The checkpoint and Delta transaction log work together as a distributed two-phase commit. The checkpoint tracks intent, while Delta’s log tracks completion. Both must agree for the system to move forward.
Offset Semantics / ( inclusive, exclusive]
When reading from Kafka, understanding offset boundaries is crucial for reasoning about what each batch consumes.
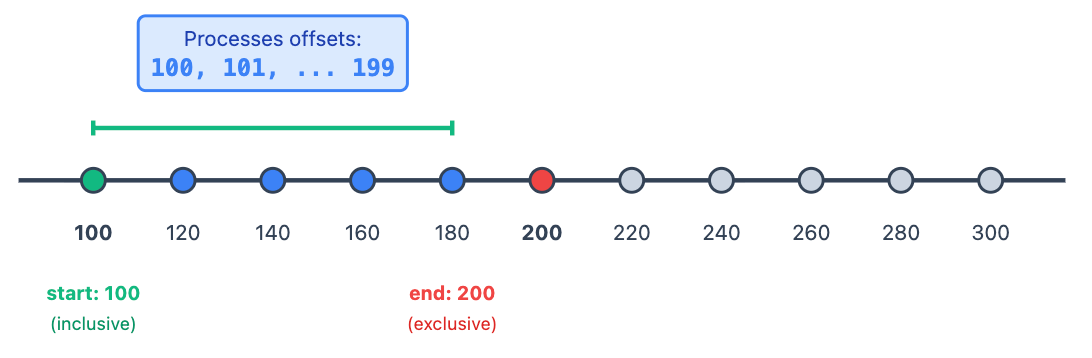
Start Offset: Inclusive- If start = 100, offset 100 is included in the batch
End Offset: Exclusive- If end = 200, offset 200 is not included in the batch
Next Batch: Batch N+1 would start at offset 200(the previous end becomes the next start)
TLDR: Recovery Rules

Where to Find the IDs
Streaming Query ID
📁Checkpoint
metadata/file🖥️Spark Streaming UI (while query runs)
📓Notebook outputs showing query status
Batch/Epoch IDs
📊Tracked per micro-batch (0, 1, 2, ...)
🏷️Used by Delta to prevent duplicate commits (same as epochId)
📜Visible in Delta transaction log
When Things Go Wrong: A Real-World Accident
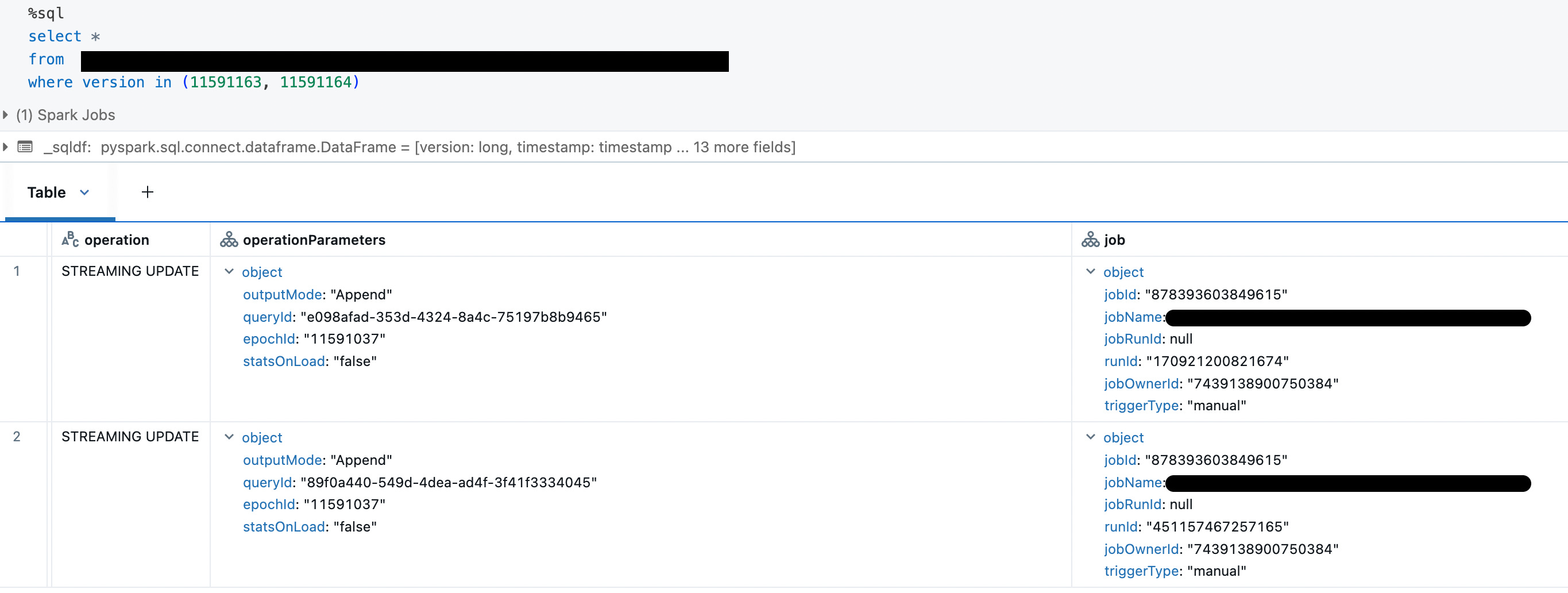
I encountered a scenario where duplicate records appeared in my Delta Lake table despite Structured Streaming’s exactly-once guarantees. The quickest way to identify the scope of the problem was using Delta’s _metadata column to pinpoint which Parquet files contained duplicates. By tracing these files back through the Delta transaction log versions, I discovered the root cause: the same epochId appeared in multiple transactions with different queryId values. This broke Delta Lake’s idempotency mechanism, which relies on the unique combination of (queryId, epochId) to detect and skip duplicate writes.
Root Cause
The checkpoint directory was accidentally overwritten or corrupted, causing Spark to reinitialize with a new queryId while replaying already-processed batches. Since Delta only saw new queryId values, it treated these as legitimate new transactions rather than duplicates, resulting in data duplication.
Key Lessons:
This incident brought to light the critical importance of:
Enable comprehensive logging Implement S3 Server Access Logging or AWS CloudTrail to audit all checkpoint location and detect unauthorized changes
Implement strict access control on checkpoint directories to prevent accidental modifications or deletions using UC Volumes
Treat checkpoint directories as critical infrastructure requiring the same level of protection and operational discipline as your data itself
Critical Takeaway: While Spark and Delta Lake provide strong exactly-once semantics, the checkpoint directory is a critical piece of infrastructure that requires the same level of protection and monitoring as your data itself.
Summary: The Complete Picture
Checkpoint structure:
offsets/tracks what to process,commits/tracks what’s been completedTiming matters: Offsets written before processing, commits written after success
Delta Lake’s role: Transaction log with (query ID, epoch ID) prevents duplicates
Safe replay: If a batch is replayed, Delta checks for prior commit and skips if found
Exactly-once guarantee: Together, checkpoint + Delta transaction log ensure no data loss or duplication
Related Deep Dives:
If you found this troubleshooting walkthrough helpful, I have a couple of other related posts that dive deeper into Delta Lake forensics and data management:
Forensic Analysis: I’ve written a detailed guide on how to trace exactly which Delta version number, Parquet file, and commit produced specific records, including sample code for the investigation process. If there’s interest, I’m happy to write a dedicated breakdown on this methodology—just leave a comment below!
Handling Data Deletion: When you need to delete data from Delta Lake tables, understanding the impact on downstream streaming consumers is critical. I’ve covered this scenario in depth, including patterns for safe deletion and stream recovery. Check it out here: How to Actually Delete Data in Spark
📺 Deep Dive into Stateful Stream Processing in Structured Streaming
This talk covers the internals of stateful stream processing, checkpoint mechanisms, and recovery patterns in production environments. It provides invaluable insights into how Spark manages state and handles failures at scale.
Let me know in the comments if you’d like to see more operational war stories and troubleshooting techniques!

