
Why Your PySpark UDF Is Slowing Everything Down
An in-depth exploration of architecture, execution flow, bottlenecks, and optimization strategies for PySpark UDFs

1. Introduction
PySpark’s User Defined Functions (UDFs) empower developers to inject custom Python logic into Spark DataFrames. They feel like a convenient escape hatch when built-in SQL functions don’t cut it. However, under the hood, each UDF invocation triggers a complex ballet of inter-process communication, serialization, and single-threaded Python loops. This blog peels back each layer of that architecture to reveal why PySpark UDFs can become a massive performance drain — and then walks through concrete alternatives and optimizations to keep your jobs blazing fast.
2. The Problem with PySpark UDFs
When you sprinkle UDF calls across your Spark SQL or DataFrame pipeline, you’re effectively handing off portions of your query plan to a “black box” Python function. That comes at a steep cost:
2.1 Catalyst Optimizer Becomes Blind
No predicate pushdown: Spark’s Catalyst optimizer can’t inspect or reorder the logic inside your UDF, so it abandons optimizations like pushing filters down to data sources.
No whole-stage code generation: The code-gen engine can’t fuse your UDF into JVM bytecode, so you lose out on compiler-level speed gains.
2.2 Serialization/Deserialization Overhead
Row-by-row data shuffling: Each row must be marshalled from the JVM heap into a Python object, sent over a local socket, then converted back. After your Python code runs, the result takes the reverse path back into the JVM.
Millions of crossings: With millions (or even billions) of rows, that boundary-crossing cost balloons.
2.3 Single-Threaded Python Execution
Global Interpreter Lock (GIL): Your UDF runs in a standard CPython process under a single core. All per-row work happens sequentially.
ide the UDF.
2.4 Memory and Stability Risks
Python OOMs: Unlike JVM operations, Spark doesn’t manage Python worker memory. Processing large batches can crash with out-of-memory errors.
Uncaught exceptions: A bug in your UDF can fail an entire Spark task. Null handling, pickling errors, and non-serializable closures often catch teams by surprise.
3. Under the Hood: PySpark’s Dual-Runtime Architecture

Py4J is a communication bridge/library that lets Python and Java interoperate by exchanging objects over sockets. In Spark, it powers two key workflows: setting up the Python SparkContext and converting data types in PySpark SQL. When you start a PySpark session, Py4J opens a socket connection between your Python driver and the underlying Java driver. Later, whenever Spark SQL operations run, Py4J translates Python types into their Java equivalents (and back) so the Python API can seamlessly drive the JVM-based SQL engine. Under the hood, every Python UDF invocation follows this path:
Python Driver → SparkContext → Py4J → JVM → JavaSparkContext Because each UDF call must cross this socket boundary, it adds measurable latency to your job.
3.1 Py4J: Bridging Python and the JVM
At startup, PySpark uses Py4J to:
Connect the Python driver to the JVM driver.
Translate data types between Python and Java during SQL operations and UDF calls.
Every call into Spark SQL or a UDF crosses this bridge — think of it as a high-latency tunnel for each record.
3.2 Driver, Executors, and Python Workers
Driver (Python process): You call
df.withColumn("foo", my_udf(col("bar"))).JVM Driver: Receives the UDF registration, plans the query.
Executor JVMs: Spin up separate Python subprocesses per task.
Python Workers: Handle the actual UDF logic on deserialized batches.
4. Lifecycle of a PySpark UDF Call
4.1 Registration & Serialization of the Python Function
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
def uppercase(val):
return val.upper()
uppercase_udf = udf(uppercase, StringType())
_create_udfwraps your Python function into a serializable form and tags it with return types.UDF object travels in the Spark plan to all executors.
4.2 Data Flow on Executors
Executor receives a task partition.
JVM serializes partition rows into Arrow or Pickle bytes.
Bytes stream over TCP to the Python worker.
Python worker deserializes, applies your function row-by-row.
Results are serialized back to JVM for further operators.
4.3 Detailed Serialization Cycle
JVM row object
└─serialize─▶ Python bytes
└─deserialize─▶ Python object
└─apply UDF─▶ Python object
└─serialize─▶ Python bytes
└─JVM bytes
└─deserialize─▶ JVM rowMultiply that by every row, every partition, every stage — and you see why simple operations feel so sluggish.
5. Performance Implications
5.1 Quantifying the Overhead
Catalyst loss: 10–30% longer query planning in UDF-heavy jobs.
Serialization tax: 0.5–5 ms per row crossing (tested on medium-sized clusters).
CPU utilization: < 25% CPU usage across nodes despite heavy transforms.
5.2 Real-World Benchmark Example
Scenario: Uppercasing a 100 million-row column.
Native Spark SQL:
df.selectExpr("upper(name) as name")→ 12 seconds end-to-end
Python UDF:
df.withColumn("name", uppercase_udf("name"))→ reorders, serialization, single-thread overhead → 85 seconds
7× slower for a trivial transform.
6. Strategies for Faster Custom Logic
6.1 Leverage Built-in Spark Functions
Whenever possible, reach for Spark’s SQL functions (upper, concat, regexp_replace, etc.) — they run entirely in the JVM, enjoy whole-stage codegen, and scale across all cores.
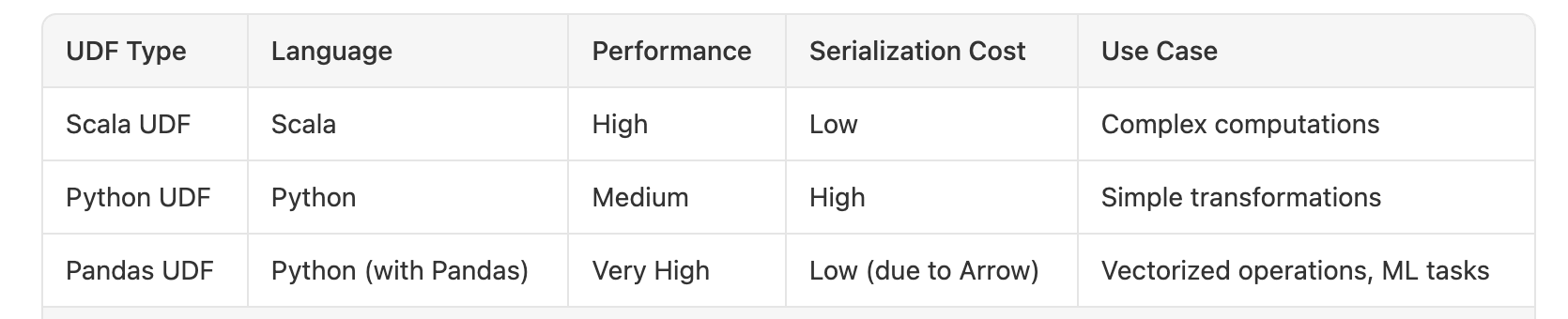
6.2 Pandas UDFs (Vectorized)
Introduced in Spark 2.3, Pandas UDFs batch rows into pandas.Series and use Apache Arrow for zero-copy transfer.
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import StringType
import pandas as pd
@pandas_udf(StringType())
def upper_series(s: pd.Series) -> pd.Series:
return s.str.upper()
df.withColumn("name", upper_series("name"))
Batch size: Typically 8 K–64 K rows per call
Vectorized ops: Internal loops in C, parallelized across cores in Python worker
Results: 5–10× speed-up over row-UDFs
6.3 Scala/Java UDFs
If you need custom logic beyond SQL but want JVM speed:
Write a Scala object implementing
UserDefinedFunction.Register it via
spark.udf.registerJava(...).Invoke from PySpark as if it were a native function.
No Python serialization needed.
Runs inside the executor JVM with full multi-core utilization.
6.4 Threading & Parallelism in Python UDFs
If you absolutely must call an external API or library row-by-row:
Use multithreading inside your Python UDF to hide network latency.
Batch HTTP calls where possible.
Be cautious: GIL still applies for CPU-bound work, and thread pools can exhaust memory.
7. Common Pitfalls & Debugging Tips
PicklingError: Ensure functions and closures reference only top-level functions and serializable objects.
Null handling: Always guard inputs with
if v is None: return None.Schema drift: Explicitly set return types; mismatches lead to confusing errors at shuffle boundaries.
Memory leaks: Monitor Python worker logs for
MemoryErrorand tunespark.python.worker.memory.
8. Summary & Best Practices
Our newsletter is 100% free and always will be, but without your claps, comments, or shares, search engines may bury this post forever. A quick clap not only tells us this content resonates but also makes sure you (and everyone else) can find it again when it matters most.
Avoid plain Python UDFs whenever built-in Spark SQL functions suffice.
Prefer Pandas UDFs for vectorized, batch transforms—they dramatically reduce boundary crossings via Apache Arrow. In fact, the vectorized nature and rapid Arrow improvements often make Pandas UDFs faster than even Scala/Java UDFs.
Consider Scala/Java UDFs only when you need JVM-native logic that can’t be expressed in SQL or Pandas UDFs.
Design for serializability: keep UDFs self-contained, stateless, and null-safe.
Benchmark early: compare native vs. Pandas vs. Python vs. Scala/Java UDFs on representative data.
Moving forward, hands down use native functions first, then Pandas UDFs in almost all cases.
When you must call external APIs inside a UDF loop, embed threading or async parallelism to help latency—see this video on parallelization within a loop for an example.
By understanding the multi-stage journey of data through the PySpark UDF pipeline — from JVM serialization, through Python’s single-threaded interpreter, back to the JVM — you can make informed choices that balance flexibility with performance. Next time you need custom logic, pause to ask: “Can I batch or vectorize? ” Your cluster (and your users) will thank you.
To learn more about how to improve things, read our deep dive blog on Pandas UDF.

References
Ganesh, R. “Is really UDF hitting the performance in PySpark!” Medium, Jul 5, 2024. Medium
AWS Documentation. “Optimize user-defined functions,” Tuning AWS Glue for Apache Spark (AWS Prescriptive Guidance). AWS Documentation
Tang, T. “Spark functions vs UDF performance?” Stack Overflow, Mar 5, 2018. Stack Overflow
Databricks. “Arrow-optimized Python UDFs in Apache Spark™ 3.5,” Databricks Blog, Aug 26, 2024. Databricks
“Why You Should Avoid Using UDFs in PySpark,” Det.Life Blog, Jan 2024. Data Engineer Things
Illustrious_Ad4259. “Are there any major disadvantages in performance for Spark when using PySpark?” Reddit r/dataengineering, Nov 2021. Reddit
Sen, Soutir. “PySpark UDFs (User-Defined Functions) – Complete Guide,” LinkedIn Article, Dec 2024. linkedin.com
Two Sigma. “Introducing Pandas UDFs for PySpark,” Two Sigma Article.